6. 배포
지속적 통합(CI/Continuous Integration)
- CI를 통한 핵심 목표는 모든 사람이 서로 동기를 맞추는 것
- 새롭게 체크인된 코드가 기존 코드와 적절히 통합됨을 보장함으로 달성할 수 있음
- CI 서버는 아래에 대한 검증을 함
- 코드의 커밋을 감지
- 체크아웃
- 코드의 컴파일과 테스트 통과를 확인
CI 장점
- 코드 품질에 대해 어느 정도 바른 피드백을 얻을 수 있음
- 바이너리 산출물을 자동으로 생성
- 산출물의 빌드를 위한 모든 코드는 버전 관리 되므로 필요할 때 언제든지 다시 만들 수 있음
- 배포된 산출물의 코드를 찾을 수 있는 정도로 추적할 수 있음
- CI 도구 자체의 기능에 따라 코드와 산출물에 대해 어떤 테스트가 수행되었는지 확인 가능
제즈 험블의 3가지 질문
- Q. 하루에 한번 메인 브랜치에 체크인하는가?
- 나의 코드는 물론 다른 사람들이 변경한 코드 또한 자주 확인하지 않는다면 향후의 통합이 더 어려워짐.
- 내 피처 개발을 위해 별도의 브랜치를 사용하고 있더라도 가능한 한 자주 메인 브랜치에 통합 해야 함
- Q. 변경을 확인할 테스트 집합이 있는가?
- 테스트를 하지 않는다면 통합해서 작동하는지 구문상으로만 알 수 있으며, 시스템의 동작을 중단시키는 것까지는 알 수 없음
- 코드가 기대한 대로 동작하는지 검증하지 않는 CI는 CI가 아님
- Q. 빌드가 깨졌을 때 팀이 그것을 최우선으로 해결하는가?
- 녹색 빌드는 변경한 것이 안전하게 통합되었고, 적색 빌드는 마지막 변경이 통합되지 않았음을 의미
- 우리는 빌드 문제의 해결과 관련 없는 추가적인 체크인을 중단해야 한다. 변경이 많이 적체되면 그 빌드를 해결할 시간이 급격히 늘어남
- 필자는 수일 동안 필드가 깨어진 채로 방치한 티과 함께 작업했었는데, 결국 빌드를 통화하는 데 엄청난 노력이 듬
CI는 빠르고 신속한 변경을 위한 핵심적인 실천 사항
- CI 없이는 마이크로서비스를 향한 여정이 고통스러울 것
- CI 도구의 사용과 CI의 실천을 혼동하지 말 것
- CI 도구는 단지 이러한 접근을 가능하게 할 뿐
CI를 마이크로서비스와 매핑하기
- 마이크로서비스당 하나의 CI 빌드 구성
- 실환경에 배포하기 전에 신속히 변경하고 확인하기 위함
- 각 마이크로서비스는 각자의 CI 빌드에 매핑된 각각의 소스 코드 저장소를 가짐
- 팀의 소유권도 훨씬 명확히 정리됨으로써 서비스의 소유는 저장소와 빌드도 책임지는 것을 의미
- 테스트는 마이크로서비스 소스 코드가 있는 소스 컨트롤 시스템에 있어야 함
- 특정 마이크로서비스에 대해 어떤 테스트가 수행되어야 하는지 언제든지 알 수 있어야 함
- 호스트와 서비스 매핑 관계
On-demand computing platform/주문형 컴퓨팅 플랫폼
- 컴퓨팅 자원의 비용을 대폭 낮춤
- 가상화 기술의 향상으로 조직 내 호스팅된 인프라스트럭처에 대해 더 많은 유연성 제공
- 시스템이 제로-다운타임을 허용하지 않는다면 실환경에 배포 시 다운타임이 늘어날 수 있음
- 7장에서는 green/blue 배포와 같은 모델은 구버전의 서비스를 오프라인하지 않고도 신버전의 서비스를 배포할 수 있게 하면서 이러한 불편을 완화
- 이 기동 시간(spin-up time)을 줄이기 위한 한 가지 방법은
공통적으로 의존하는 것들을 주입한 가상 머신 이미지를 만드는 것
AWS EC2 Instance를 프로비전하고 그 안에서 LXCs1 실행
매우 유연한 EC2의 형태로 대표되는 on-demand computing platform과
그 위에서 빠르게 실행되는 컨테이너의 조합
7. 테스팅
Unit Test
- 일반적으로 단일 함수 또는 메서드 호출을 테스트하는 것
- 기능의 정상 동작 유무에 대한 매우 빠른 피드백
- 코드를 재구성하게 해주며, 작은 범위의 테스트들이 실수를 잡아주기 때문에 코드의 리팩토링을 지원하는 데 있어 중요
- 문제를 신속히 발견하고 해결하기 위해 테스트를 더욱 격리하기 위함
- 격리를 위해 모든 외부 협업자를 스텁으로 만들어 오직 서비스 자체의 범위만으로 제한
테스트 작성 전담 팀은 재앙
- 소프트웨어를 개발하는 팀은 그들의 코드에 대한 테스트와 점차 멀어짐
- 서비스 소유자들은 방금 개발한 기능의 E2E 테스트를 테스트 팀이 작성할 때까지 기다려야 하므로 사이클이 길어짐
- 다른 팀에 이 테스트를 작성하기 때문에 서비스를 개발했던 팀은 덜 참여하게 되고 이들은 테스트를 어떻게 고치는지 모르기 쉬움
Green/Blue Deployment
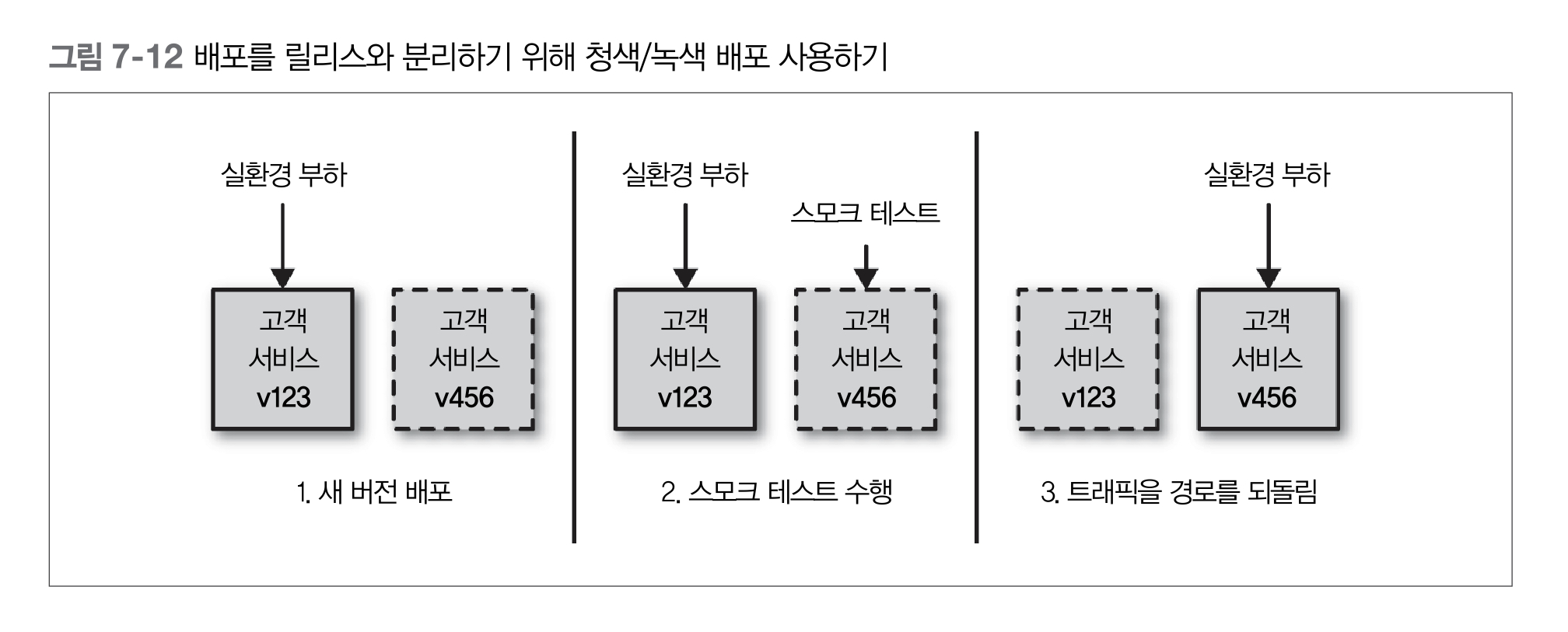
- 동시에 배포된 신/구 버전의 소프트웨어중에서 한 버전만 실제 요청을 처리
- 실환경 트래픽을 다른 호스트(또는 호스트의 집합)로 향하게 할 수 있어야 함
- 부하 분산 설정(load-balancing configuration)을 변경하는 식으로 가능
- 한 번에 두 버전의 마이크로서비스를 프로비저닝할 수 있어야 함
- 탄력적인 클라우드 제공자(elastic cloud provider)를 사용하면 간단한 일
- 배포의 위험을 낮출 뿐만 아니라 문제가 발생했을 때 롤백이 빠르게 가능함
- 전체 프로세스가 사람의 개입이 전혀 없이도 모든 전개와 복귀가 자동화될 수 있음
- 무중단 배포(zero downtime deployment)
- 릴리즈 작업을 수행하는 동안 과거 버전을 유지함으로써 시스템의 정지 시간을 크게 낮출 수 있음
Canary Release
- 카나리 릴리스를 했을 때 시스템이 예상대로 수행하는지 보기 위해 실환경 트래픽을 유입시켜 새롭게 배포된 소프트웨어를 검증
- 새 릴리스가 잘못되었다면 신속히 되돌려야 함
- 새 릴리스가 정상이라면 늘어나는 트래픽이 새 버전에 유입되도록 해야함
- 카나리 릴리스는 버전들이 더 오래 공존시킬 수 있고 트래픽의 양을 자주 변경할 수 있다는 점에서 green/blue release와 차이가 있음
- 장점
- 나쁜 릴리스의 출시 위험을 관리할 도구를 제공하며
- 실제 트래픽으로 새 버전의 소프트웨어를 검증할 수 있게 함
- 단점
- 하지만 green/blue release 배포보다 복잡한 설정과 약간의 사고를 더 필요로 함
- 서로 다른 버전의 서비스가 green/blue release보다 더 오랜 기간 공존할 것이 예상되므로 이전보다 더 많은 하드웨어를 점유할 수 있음
- 새로운 릴리스의 동작을 확신하기 위해 트래픽 비율을 조정해야 하기 때문에 더 정교한 트래픽 라우팅도 필요
- 하지만 이미 green/blue release를 다루고 있다면 필요한 구성 요소 일부는 이미 갖춘 셈
- 넷플릭스 사례
- 릴리스에 앞서 실환경과 동일한 버전을 표현하는 기반 클러스터에 새로운 서비스 버전이 함 께 배포
- 그 다음에 수 시간 동안 새 버전과 기반버전 양쪽에 실환경의 부하 일부를 주면서 측정
- 카나리 릴리즈가 테스트를 통과하고 나면 넷플릭스는 실환경에 전체 전개를 진행
MTBF & MTTR
MTBF/Mean Time Between Failure : 평균 무고장 시간
MTTR/Mean Time To Repair : 평균 수리 시간
복구 시간을 줄이는 기술은 청색/녹색 배포와 같은 훌륭한 모니터링과 결합되어 아주 빠른 롤백만큼 단순할 수 있음
실환경의 문제를 일찍 발견하고 롤백할 수 있다면 고객에게 적은 영향을 줄 수 있음
물론 사용자가 새 버전의 소프트웨어를 접하기 전에 그것을 배포하고 바로 테스트할 수 있는 청색/녹색 배포와 같은 기술도 사용할 수 있음
기능 테스트 집합을 생성하는 데 시간을 보내는 대부분의 조직은 대게 더 나은 모니터링이나 장애 복구에 전혀 공을 들이지 않음
그들은 처음에 발생하는 많은 결함을 줄일 수 있지만, 전부 제거하지는 못하고 실환경에서 장애가 발생할 때 처리할 충분한 준비도 하지 못함
8. 모니터링
- 모니터링이란?
- 모놀리식 애플리케이션의 세계에서는
- 적어도 분석을 시작할 아주 명확한 지점
- 단일 장애 지점(single point of failure)이 있다는
- 장애 분석을 다소 쉽게 만들 수 있어야 함
- 단일 서버/서비스, 다수 서버/서비스 등이 만드는 모든 것을 취합하고 세부 분석
- 로그부터 애플리케이션 측정 지표까지 가능한 한 많은 수집과 집중식 취합
- 모놀리식 애플리케이션의 세계에서는
- logstash
- 많은 로그 파일 포맷을 파싱하고 추가 분석을 위해 하부 시스템에 전송할 수 있음
- Kibana
- 로그를 보기 위한 일레스틱서치 기반 시스템(Elastic Search-backed system)
- 로그 검색을 위한 질의 구문(query syntax)과 특정 날짜와 시간 범위 또는 일치하는 문자열으르 찾기 위한 정규식도 사용할 수 있음
- 전송된 로그에서 그래포도 생성 가능, 시간에 따라 얼마나 많은 에러가 발생했는지 한번에 보는 것이 가능
- Metrics
- 복잡한 환경에서는 서비스들의 인스턴스가 매우 빈번히 프로비저닝되기 때문에
- 우리가 선택한 시스템이 새로운 호스트로부터 측정지표를 매우 쉽게 수집하기 원함
- Graphite/그래파이트
- 평균 CPU 부하와 같이 전체 시스켐에 대해 집계된 특정 측정지표를 볼 수 있기를 기대하지만
- 특정 서비스에 대한 모든 인스턴스나 개별 인스턴스에 대한 측정지표까지도 집계되기 원함
- 이러한 구조를 추론할 수 있도록
메타데이터와 측정지표를 연결할 수 있도록 매우 쉽게 만들어주는 시스템 - 단순한 API를 제공해서 실시간으로 측정지표를 전송할 수 있고
- 현재 상황을 보여주는 차트나 다른 형태의 디스플레이를 생성하기 위해 그 측정지표에 대한 질의도 할 수 있음
여러 표본을 취합하고 한 표본을 따라 자세히 검색함으로써 전체 시스템, 서비스 그룹 또는 단일 인스턴스에 대한 응답시간을 알 수 있음
상관관계 ID
stack strace로 한 것처럼 상향 호출 체인을 추적할 수 있음- 첫 호출이 이뤄질 때 호출에 대한 전역 호출 식별자(GUID, globally unique identifier)를 생성
- 후속하는 모든 호출에 전달 -> 로그 레벨이나 날짜와 같은 구성 요소와 함께 구조화된 방식으로 로그에 넣을 수 있음
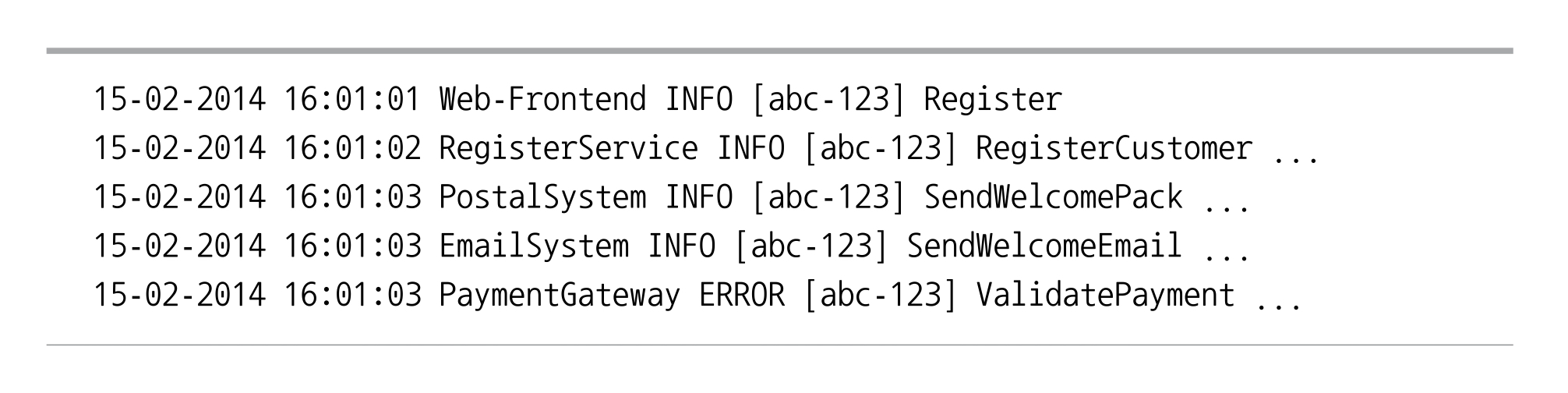
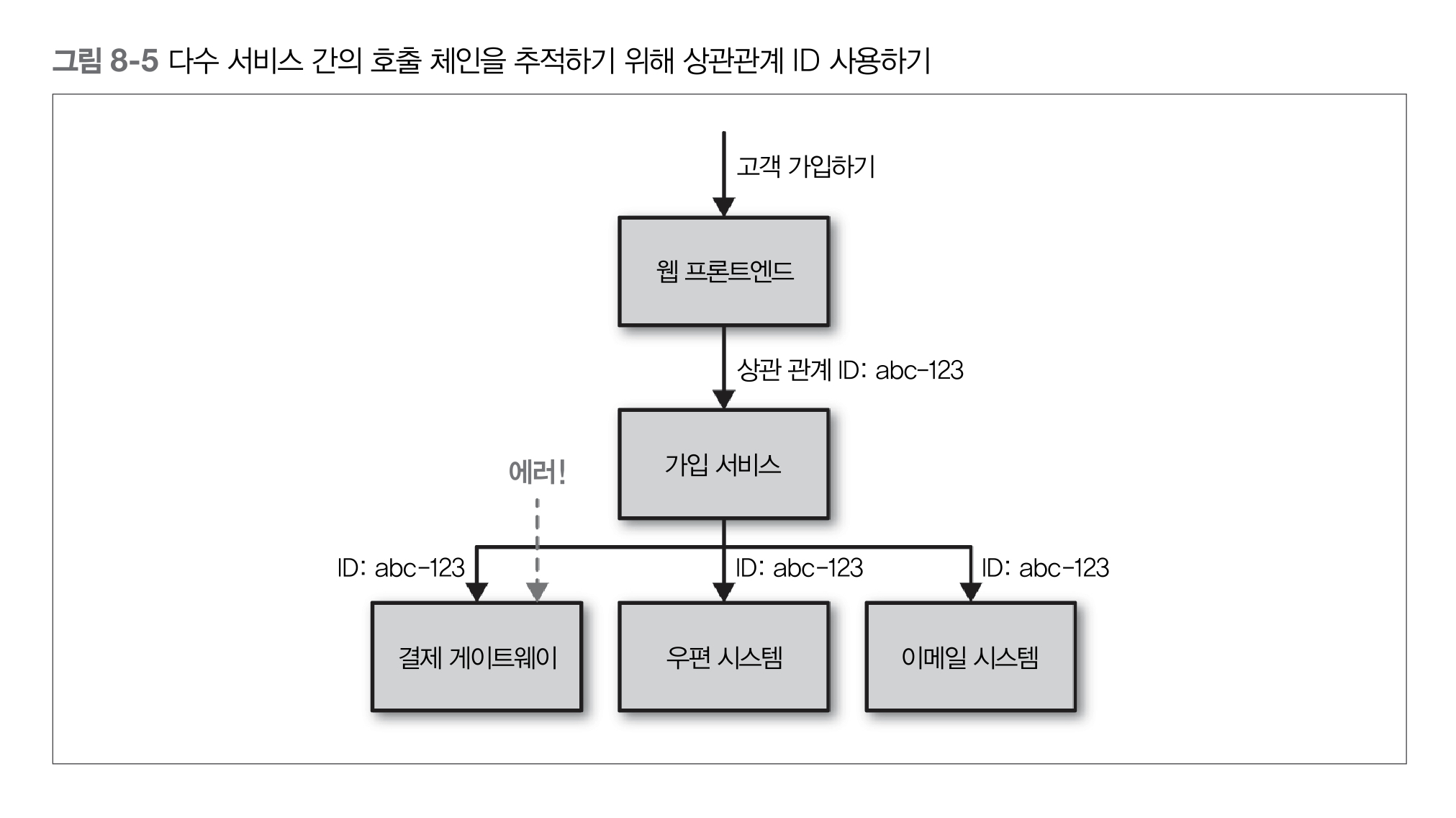
하지만 처음부터 상관관계 ID가 있어야만 분석할 수 있는 문제를 접하기 전까지 상관관계 ID의 필요성을 모른다는 것!
통합 모니터링
- 시스템간의 통합 지점 모니터링 중요
- 각 서비스 인스턴스는 다른 서비스에 이르기까지 하위 의존성 상태를 추적하고 노출
- 모니터링은 표준화가 매우 중요한 분야
- 많은 인터페이스를 이용하는 사용자에게 기능을 제공하기 위해 다양한 방식으로 협업하는 서비스들이 있다면
- 총제적인 방식으로 시스템을 바라볼 수 있어야 함
- 표준 포맷으로 로그를 출력
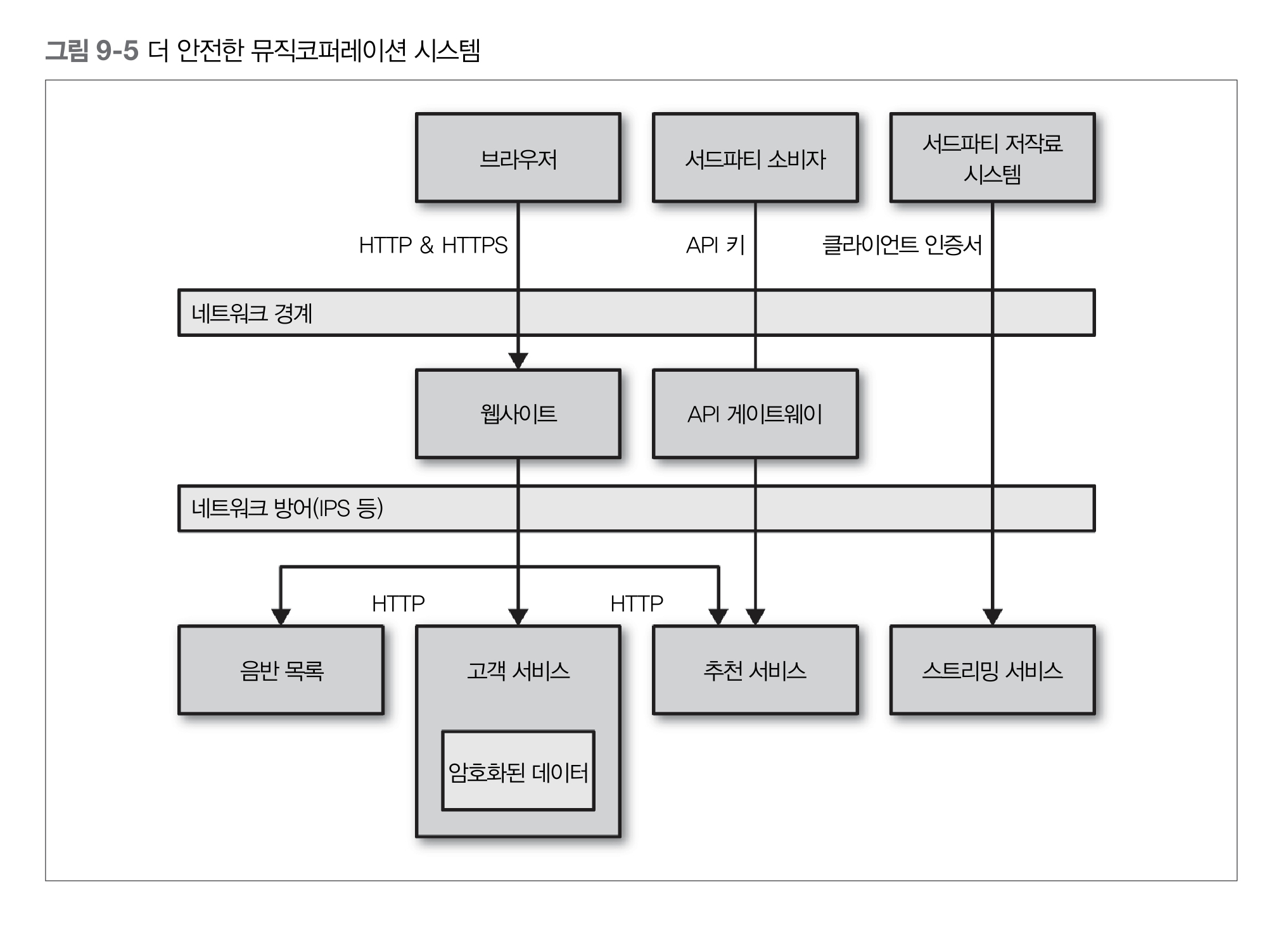
9. 보안
인증(authentication)과 권한부여(authorization)는 시스템과 상호작용하는 인간과 사물에 있어 핵심적인 개념
- 보안의 맥락에서 인증은 자신이라고 말하는 당사자를 확인하는 과정
- 인증되는 사람 또는 사물에 대해 추상적으로 말할 때 그 대상을 principal로 언급
목표는 한 번의 인증으로 모든 시스템을 이용할 수 있는 single identity를 보유하는 것
SSO/Single Sign-On
예를 들어 어느 컴퓨터에 로그인한 후 그룹웨어 등의 응용 프로그램을 사용할 때에 로그인,
다른 서버상의 응용 프로그램을 사용할 때에도 다시 로그인이 필요한 상황이라면,
사용자는 여러 개의 아이디와 비밀번호를 관리해야 한다.
통합인증을 도입한 환경에서는 사용자는 하나의 아이디와 비밀번호로 모든 기능을 사용할 수 있다.
SSO 장단점
- 보안이 필요한 환경에서 통합인증을 도입하는 경우
- 여러 응용 프로그램의 로그인 처리가 간소화되어 편리성을 도모할 수 있음
- 하지만 최초의 로그인 대상이 되는 응용 프로그램 혹은 운영체제에 대한 접근 보안이 중요함
- 보안위험이 적은 환경에서는 편리성만을 추구하면 되지만
- 보안이 요구되는 환경에서는 1회용 비밀번호를 이용하는 등 이중 인증 등으로 보안을 강화할 필요가 있음
- 보안이 필요한 환경에서 통합인증을 도입하는 경우
SAML/Security Assertion Markup Language, 샘엘
- 인증 정보 제공자(identity provider)와 서비스 제공자(service provider) 간의 인증 및 인가 데이터를 교환하기 위한 XML 기반의 개방형 표준 데이터 포맷
- SOAP 기반의 표준이며 지원 가능한 라이브러리와 도구가 있음에도 불구하고 작업이 꽤 복잡
- 출처 - 위키백과
- SAML에 대해 알아야 할 것들
openID Connect
- openID Connect 는 openid라는 scope 값을 포함해서 Authorization Request를 보내며 Authentication에 대한 정보는 ID Token 이라고 불리는 JSON Web Token(JWT)을 리턴
- OAuth 2.0의 특정 구현에서 출발한 표준
- 구글 및 다른 업체에서 SSO를 처리하는데 사용
- 더 단순한 REST 호출을 사용하고, 사용 편의성이 향상되어 기업 시장으로 진출
LDAP/Lightweight Directory Access Protocol
- 기업의 경우에는 흔히 회사의 디렉터리 서비스와 연결될 수 있는 자체 신원 제공자를 보유
- 디렉터리 서비스 LDAP, 경량 디렉터리 액세스 프로토콜
Okta
- 이중 요소 인증과 같은 작업을 처리하는 SAML 신원 제공자 호스팅 서비스지만,
- 여러분 회사의 진위 출처 디렉터리 서비스도 연결 가능
세분화된 권한 부여
게이트웨이는 상당히 효과적인 큰 단위의 인증 기능을 제공하는 것이 가능
로그인이 안 된 사용자의 헬프데스크 애플리케이션에 대한 접근을 차단할 수 있음
특정 자원 또는 엔드포인트에 대한 접근의 허용 여부는 마이크로서비스 자체에 맡겨야 함
- 어떤 행동의 허용 여부는 마이크로서비스가 더 많이 결정해야 할 필요가 있음
HTTP(S) 기본 인증
- HTTP Basic Authentication은 클라이언트가 사용자 이름과 패스워드를 표준 HTTP헤더에 넣어서 전송
- 서버는 상세 내용을 확인하고 클라이언트의 서비스 접근 허용 여부를 승인
- 하지만, 안전한 방식으로 사용자 이름과 패스워드를 전송할 수 없으므로 문제가 많음
- 네트워크상의 어떠한 중간자도 헤더 정보와 데이터를 볼 수 있으므로 HTTP 기본 인증은 대개 HTTPS 상에서 수행되어야 함
- HTTPS를 사용하면 클라이언트는 통신하고 서버가 자신이 생각하는 그 서버라는 확실한 보장을 받고
- 클라이언트와 서버 간의 트래픽을 도청하거나 페이로 조작을 막는 추가적인 보호도 받음
- HTTP Basic Authentication은 클라이언트가 사용자 이름과 패스워드를 표준 HTTP헤더에 넣어서 전송
SAML 또는 OpenID Connect 사용하기
- 게이트웨이를 사용하고 있다면 네트워크 내부의 트래픽을 게이트웨이로 라우팅해야겠지만
- 만약 개별 서비스가 직접 서비스 간 통합을 처리한다면 이 라우팅을 기본적으로 지원해야 함
- 기존의 인프라스트럭처를 사용할 수 있고 모든 서비스의 접근 통제를 중앙의 디렉터리 서버에 모아서 처리할 수 있음
- 중간자 공격을 피하고자 한다면 여전히 HTTPS 상에서 라우팅해야 함
클라이언트 인증서
- 클라이언트의 신원 확인을 위한 또 다른 방법은 (SSL의 계승자인) 클라이언트 인증서 형태의 전송 계층 보안(TLS/Transport Layer Security) 기능을 이용하는 것
- 클라이언트와 서버의 연결을 체결할 때 사용되는 X.509 인증서가 각 클라이언트에 설치되어 있으며,
- 서버는 클라이언트 인증서의 진위를 검증하여 유효한 클라이언트인지 확실히 보장할 수 있음
HTTP 기반의 HMAC
- HTTPS 트래픽이 서버에 부담을 줄 수 있고, HTTPS 트래픽은 캐시하기도 쉽지 않음
- 다른 대안은 OAuth 명세서 일부와 AWS S3 API에 의해 폭넓게 사용되는 해시 기반 메시징 코드(HMAC/hash-based messaging code)를 HTTP 요청의 서명에 사용하는 것
- HMAC 장점
- HMAC에서 요청 메시지 바디는 비밀 키를 사용해서 해시되고 해시 결과는 요청과 함께 전송
- 서버는 자신이 가진 비밀 키의 복제본을 사용해서 해시를 재생성
- 1과 2가 일치한다면 서버는 그 요청을 수락
- 누군가 중간에 요청을 변조한다면 해시는 일치하지 않을 것이고, 서버는 그 요청이 변조되었다는 것을 알 수 있음
- 비밀 키는 절대 그 요청에 넣어 전송하지 않으므로 통신상에서 누출 될 수도 없음
- 트래픽이 더 쉽게 캐쉬되고, 경우에 따라 다르겠지만 아마도 해시를 생성하는 부하가 HTTPS 트래픽을 처리하는 것보다 더 낮다는 추가 이점
- HMAC 단점
- 클라이언트와 서버 모두 어떤 방식으로든 통신해서 기밀을 공유해야 함
- 양단간에 하드코딩할 수 있지만 기밀이 누출된다면 접근을 차단하는 데 문제가 있음
- 다른 대체 프로토콜을 통해 통신한다면 여러분은 그 프로토콜이 매우 안전하다는 것도 보장
- 하나의 패턴이지 표준은 아니므로 다양한 구현 방법이 있음
- 그 결과 이 방법에 대한 공객적이며 가용한 양질의 구현체가 부족
- 제3자가 요청 내용을 조작하지 않았다는 것과 비밀 키 자체의 기밀성(전송하지 않으므로)만 보장하는 것
- 요청한 데이터는 네트워크상에서 스누핑하는 사람들에게 여전히 노출
- 클라이언트와 서버 모두 어떤 방식으로든 통신해서 기밀을 공유해야 함
API Key
- 모든 공개 API는 API Key를 사용함
- API Key를 통해 서비스는 API 호출자를 인식할 수 있고 호출자의 능력에 제한을 둘 수 있음
- 모두를 위한 서비스 품질을 유지하기 위해 특정 호출자에 대한 속도 제한을 할 수 있음
- 일부 시스템은 하나의 공유 API Key를 이용해서 앞에서 설명한 HMAC과 유사한 방식을 사용
- 더 일반적 방법은 공개 키와 개인키를 짝으로 사용하는 것
- 전형적으로 사람들의 신원을 한 곳에서 관리하듯이 키도 한 곳에서 관리하는데 이 분야에서는 흔히 게이트웨이 모델을 사용
- API key 기반의 인증은 SAML 핸드셰이킹 처리와 비교하면 훨씬 더 단순하고 직관적
네트워크 분리(망분리)
- 마이크로서비스에서는 서비스들의 상호 통신 방법의 통제를 세분화하도록 서비스들을 다른 네트워크 세그먼트에 배치할 수 있음
- AWS는 가상 사설 클라우드(Virtual Private Cloud/VPC)를 자동적으로 프로비저닝하는 기능을 제공
10. 콘웨이의 법칙과 시스템 설계
two-pizza team 법칙
- 팀의 규모가 피자 두판으로 식사를 마칠 수 없는 규모가 돼서는 안 된다
- 넷플릭스는 아마존의 사례를 교훈삼아 처음부터 작고 독립적인 팀을 조직했고
- 그 결과 독립적인 팀을 조직, 독립적인 서비스를 만들 수 있었음
- 변경 속도에 최적화된 시스템 아키텍처를 확보할 수 있었음
공유 서비스의 추진
- 소유권은 요구사항의 발굴에서부터 애플리케이션이 빌드, 배포, 유지보수에 이르는 모든 측면까지 확장
- 마이크로서비스에서 더 만연한 모델로, 작은 팀이 작은 서비스를 소유하기 더 용이
- 소유권 확대는 자율성 향상과 빠른 출시로 이어짐
- 애플리케이션의 배포와 유지보수까지 한 팀이 책임지게 하면 그 보상으로 배포하기 쉬운 서비스가 만들어짐
방치된 서비스
- 내부 오픈 소스 모델을 훌륭히 지원하기 위해 여러분은 몇 가지 도구가 필요
- pull 요청 또는 이와 유사한 기능을 가진 분산 버전 관리 도구는 필수
- 탑재한 코드 리뷰 시스템이거나 아닐 수도 있지만 패치에 대한 인라인 코멘트는 매우 유용한 기능
- 우리는 경계가 있는 콘텍스트 주위로 서비스의 경계선을 긋는다
다양한 기술 스택을 사용하는 폴리글랏 방식(polyglot approach)을 적용한 경우
여러분 팀이 더 이상 그 기술 스택을 모른다면 방치된 서비스를(orphaned service) 변경하는 것은
심각한 문제가 될 수 있음
11. 대규모 마이크로서비스
분산 컴퓨팅의 오류
분산 컴퓨팅에서 아키텍트나 설계자가 범하기 쉬운 7가지 가정을 소개했고,
그 후 제임스 고슬링이 다른 오류를 추가해서 분산 컴퓨팅의 8가지 오류로 알려짐
어떤 것이든 고장날 수 있다는 가정을 명심하는 것은 문제의 해결 방법을 다르게 생각하도록 만든다
AntiFragile
넷플릭스는 안티프래질 조직의 개념을 형성
넷플릭스가 전적으로 AWS 인프라스트럭처에 기반한다는 사실
이 두 요소는 장애를 잘 수용해야 한다는 것을 의미, 장애를 일부러 유발
구글은 매년 장애 복구 테스트(Disaster Recovery Test, DiRT) 훈련
Chaos Monkey
- 하루 중 특정 시간 동안 임의로 머신의 전원을 꺼버림
- 실운영 환경에서 이런 사고의 발생 가능성을 인지하는 것은 시스템을 만드는 개발자들이 실제로 그 사고에 준비하게 만듬
- 넷플릭스의 장애를 만드는 봇인 유인원 부대의 일부
Chaos Gorilla
- 전체 가용성 센터(AWS의 데이터 센터에 해당되는)를 검토하는 데 사용
Latency Monkey
- 머신 간의 느린 네트워크 접속 상황을 시뮬레이션 함
Timeout
- 모든 프로세스 경계 외부의 호출에 타임아웃을 넣고 항상 기본 타임아웃 시간을 설정할 것
- 타임아웃 발생 시간을 로깅하고 어떤 일이 발생했는지 살펴보며 타임아웃을 적절히 변경할 것
하위 시스템이 실제로 다운될 때까지 얼마나 오래 기다릴 수 있을까?
- 호출이 실패했다고 판단하는데 너무 오래 걸리면 전체 시스템이 느려질 수 있음
- 혹은 너무 빨리 타임아웃하면 동작했을지도 모르는 호출을 실패로 고려할 것
Circuit Breaker
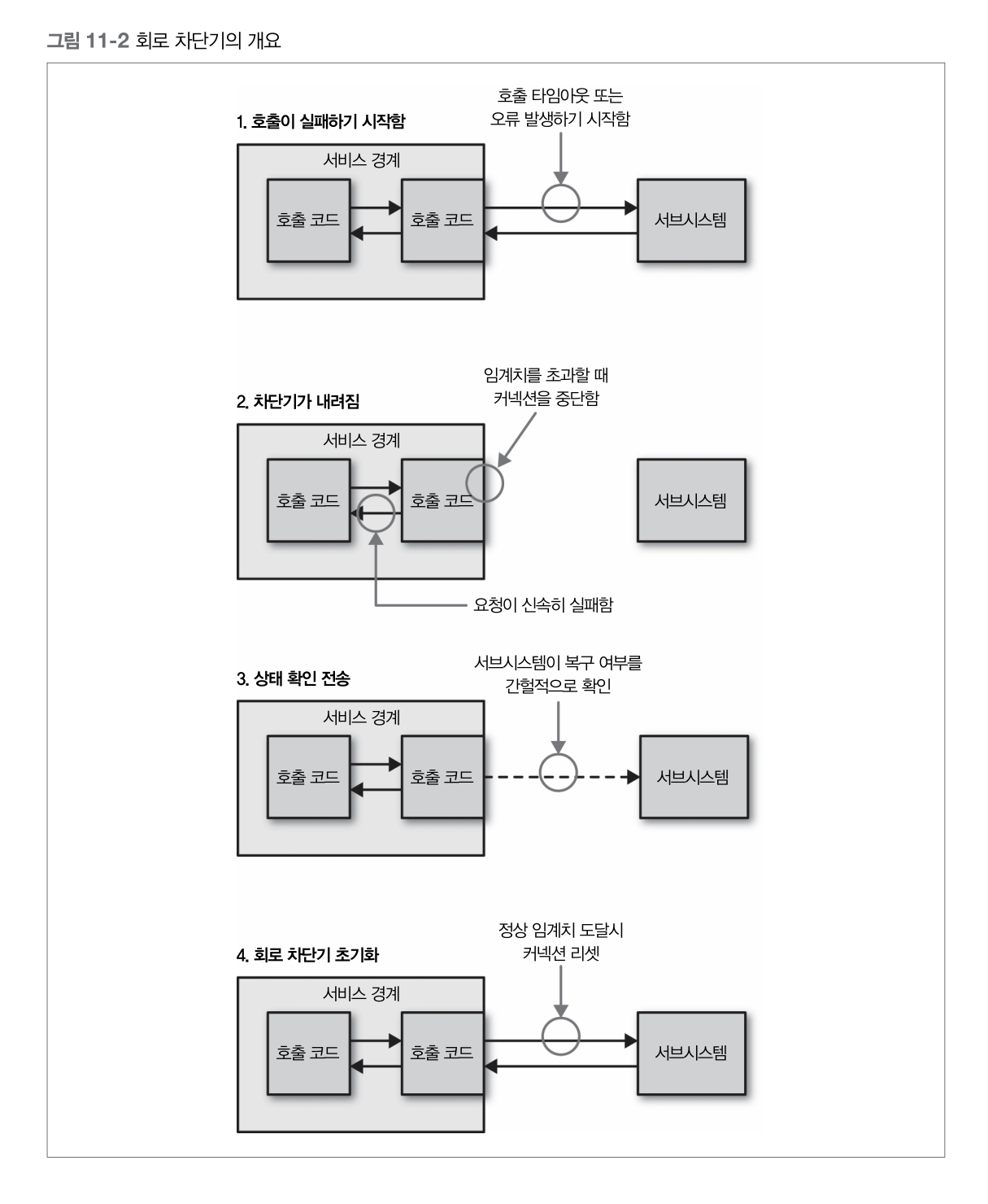
- 가정마다 전련 급등으로부터 가전 기기를 보호하기 위한 회로 차단기(Circuit Breaker)
- 회로 차단기의 구현 방법은 실패한 요청의 의미에 따라 다름
- HTTP 커넥션을 위한 차단기를 구현할 때는 타임아웃이나 5XX HTTP 응답 코드에 해당되는 호출 실패를 설정
하위 자원이 다운되거나 타임아웃되거나 에러를 리턴할 때 특정 임계값에 도달 한 후 자동적으로 전송 트래픽을 중지시키고 신속히 실패하도록 만듬- 정상으로 복구되었을 때 자동으로 재시작할 수 있음
- 회로 차단기가 끊어진 동안 할 수 있는 옵션
- 요청을 큐에 넣어두고 나중에 처리하는 것
- 비동기 작업의 일부로 작업을 수행한다면 효과적
- 호출이 동기 체인의 일부분으로 수행되는 경우에는 빨리 실패하는 것이 더 나음
- 요청을 큐에 넣어두고 나중에 처리하는 것
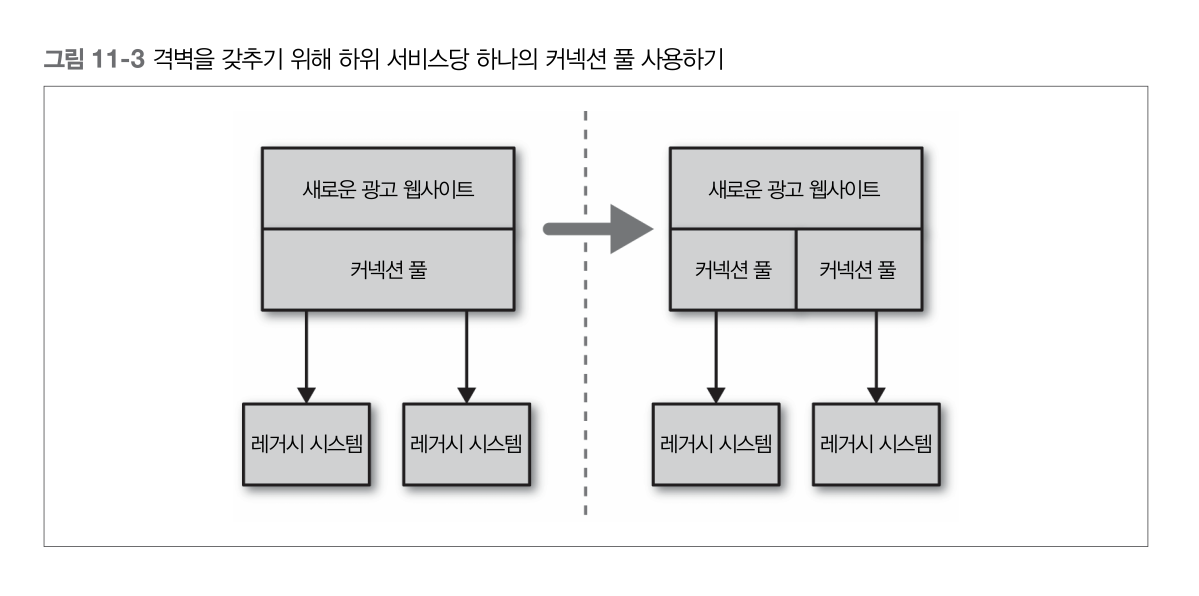
격벽
- 소프트웨어 아키텍처 측면에서 고려할 수 있는 다양한 격벽이 있음
- 각각의 하위 커넥션마다 다른 커넥션 풀을 사용해야 한다
- 이것은 특정 하위 서비스가 느려지게 되더라도 그 서비스의 커넥션 풀에서만 영향을 받고 다른 호출은 정상 처리되는 것을 보장
- 우려되는 것을 분리하는 것도 격벽의 한 방법
- 얽혀 있는 기능을 분리된 마이크로서비스로 분해함으로써 한 지역의 장애가 다른 지역에 영향을 줄 가능성을 줄임
SSL termination
- 분산기로 유입되는 HTTPS 커넥션을 HTTP 커넥션으로 변환해서 인스턴스에 전달
- 과거에는 SSL을 관리하는 부하가 상당히 높아 이 변환 과정을 처리하는 부하 분산기2를 두는 것이 매우 유용했으나,
- 요즘 이런 일은 인스턴스가 동작하는 개별 호스트를 셋업하는 것만큼 단순함
- HTTPS를 사용하는 것은 요청이 중간자 공격에 취약하지 않게 만들기 위한 것이므로,
- SSL 종단 기능을 사용하면 우리 자신을 잠재적으로 어느 정도 노출하는 것
- Virtual Local Area Network 안에 모든 마이크로서비스 인스턴스를 두는 것
ELB / Elastic Load Balancer
- AWS는 HTTPS 종단 기능이 있는 부하 분산기를 ELB형태로 제공
- VLAN3을 구현하기 위해 AWS 보안 그룹이나 가상 사설 클라우드 (VPC/Virtual Private Cloud)를 사용
데이터 확장
Standby Replica Database
- 마스터 데이터베이스에 저장된 모든 데이터가 대기 복제 데이터베이스에 복사됨
- 마스터 DB가 다운될 경우 데이터는 안전하지만,
- 그렇더라도 마스터 DB를 백업으로 바꾸거나 레플리카를 마스터DB로 승격시키는 매커니즘 없이는 DB가용성을 얻을 수 없음
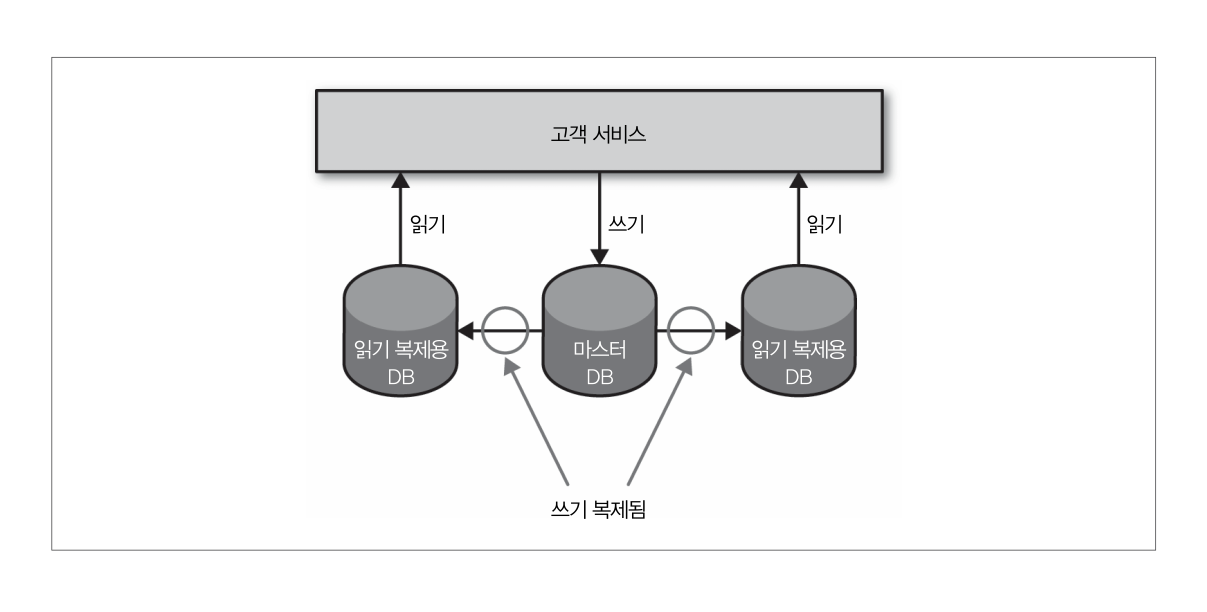
쓰기용 확장 - Sharding
- 샤딩을 통해 많은 DB Node를 가질 수 있음
- 저장할 데이터의 일부를 가지고 해싱 함수를 통해 데이터의 키를 생성하며 해싱 함수의 결과인 그 키를 사용해서 저장할 장소를 얻음
MongoDB - Map/Reduce
- 모든 샤드에 질의하고 싶다면 각각의 샤드에 질의하고 메모리에서 조인하거나 여러 데이터셋이 있는 다른 읽기 전용 저장소가 필요
- 여러 샤드에 대한 잦은 질의는 캐시 결과를 사용해서 비동기적 매커니즘으로 처리
Casandra
- 백그라운드에서 데이터의 재조정을 수행하면서 라이브 시스템에 샤드 추가를 지원
- 기존 클러스트에 샤드를 추가하는 것은 심약한 사람에게 맞지 않으므로 철저한 테스트를 잊지 말라
Caching
연산의 이전 결과를 저장해서 연속된 요청은 재연산을 위한 시간과 자원의 소비 없이 저장되어 있는 값 사용 가능
대개 캐싱은 결과를 더 빠르게 제공하기 위해 DB나 다른 서비스까지의 불필요한 왕복을 제거
Client side Caching
- 클라이언트가 새로운 복사본을 가져올 시점과 여부를 결정
- 하위 서비스가 힌트를 제공하며 클라이언트는 그 응답을 통해 해야 할 것을 이해하고 새로운 요청의 시점과 여부를 알 수 있음
- 네트워크 호출을 대폭 줄임
- 서버의 하위 서비스에 대한 부하를 줄일 수 있는 가장 빠른 방법
Proxy Caching
- 클라이언트와 서버 사이에 프로식스를 배치하는 것
- Reversed Proxy
- 스퀴드, 바니시처럼 모든 HTTP Traffic을 캐시
- CDN / Content Delivery Network
- Reversed Proxy
- 클라이언트와 서버에 독립적
- 기존 시스템에 캐싱을 추가하는 가장 간단한 방법
- 클라이언트와 서버 사이에 프로식스를 배치하는 것
Server side Caching
- Redis
- Memcached
- In-memory Cache
+ Words
snooping
- 네트워크상의 정보를 획득하는 일련의 행위를 의미
- sniffing도 유사한 의미를 가지지만 주로 염탐하는 행위를 뜻함
PaaS/Platform as a Service
- 서비스로서의 플랫폼, 대표적으로 Heroku
- Heroku는 서비스의 실행을 처리할 뿐만 아니라 아주 단순한 방식으로 데이터베이스와 같은 서비스도 지원
- 애플리케이션의 용도를 기반으로 autoscale을 시도하려는 PasS를 많이 사용했었지만 그 결과는 좋지 않았음
cascading failure/장애 전파
- 처음에 한 파트에서 발생한 장애가 연속하는 다른 파트에 장애를 촉발시키는 것
- 상호 연결된 파트의 시스템에서 발생 할 수 있음
- 이와 같은 장애는 전력 송출, 컴퓨터 네트워킹, 금융, 인체 시스템과 같은 다양한 종류의 시스템에서 발생 가능
Netflix’s Hystrix
- 지연시간 및 장애 내성 로직을 추가하여 분산 환경 서비스들 간의 상호작용을 통제하는 라이브러리
- 서비스 사이의 포인트를 격리하고 전파 장애를 막아 시스템의 회복력을 향상시킴
Netflix’s Suro
- 넷플릭스의 데이터 파이프라인 플랫폼
- 사용자 행위의 데이터와 애플리케이션 로그처럼 보다 시스템 운영적인 데이터와 연관된 두 지표 모두를 처리하는 분명한 용도
- Apache Chukwa를 기반으로 자사의 분산된 애플리케이션 서버에서 쏟아지는 엄청난 데이터를 수집해서
- S3나 하둡 파일 시스템 같은 저장소에 저장하여 실시간 분석을 도와주는 오픈 소스 플랫폼
멱등성
- 연산이 연속적으로 여러 번 적용되더라도 첫 적용 후의 결과가 달라지지 않는 성질의 연산
Swagger
- 스웨거를 사용할 경우 API를 잘 기술하면 웹 브라우저를 통해 API 문서를 볼 수 있고 API와 상호 작용할 수 있는 웹 UI를 생성할 수 있음
- LXC/Linux Container : 분리된 가상의 호스트를 구분하고 통제하기 위해 프로세스들을 위한 분리된 프로세스 공간을 생성 >자세히 보기↩
- 부하 분산. 부하 분산기 뒤에 마이크로서비스 인스턴스가 실행되는 여러 호스트를 배치하는 것으로 고용량 고비용의 하드웨어 장비에서 모드 프로식와 같은 소프트웨어 기반의 것까지 그 형태와 크기가 다양↩
- VLAN. 가상 지역 네트워크로 외부와 격리되어 있어 외부의 요청은 라우터를 통해서만 유입된다. 이 경우에는 라우터가 SSL을 종단하는 부하 분산기가 되며 VLAN 외부의 커뮤니케이션은 HTTPS로 하지만 내부에서는 모두 HTTP를 사용.↩