Apache Cassandra
Apache Cassandra는 대규모로 확장 가능한 분산 NoSQL DB로 Facebook 내부에서 시작하여 오픈소스로 출시되었습니다.
- 아파치 카산드라는 다운 타임 없이 지속적인 가용성과 고성능 및 선형 확장성을 제공합니다.
- 데이터 센터와 지역에 걸쳐 단순하고 손쉬운 복제, 페타 바이트 규모의 정보와 초당 수천 건의 동시 작업을 처리 할 수 있는 카산드라는 하이브리드 클라우드1 환경에서 대량의 데이터를 관리 할 수 있습니다.
- 성능 저하없이 확장성과 고 가용성이 필요한 경우 여러 데이터 센터와 클라우드에서 대량의 정형, 반 정형 및 비정형 데이터를 관리 할 수있는 올바른 선택입니다.
- 단일 장애 지점없이 많은 상용 서버에서 지속적인 가용성, 선형 확장 성 및 운영 단순성을 제공합니다.
- 데이터 모델은 로그 구조 업데이트의 성능, 비정규 화 및 구체화 된 뷰에 대한 강력한 지원 및 강력한 내장 캐싱을 통해 컬럼 인덱스의 편의성을 제공합니다.
카산드라의 주요 기능 및 장단점
Masterless
Master-Slave
- 전통적인 데이터베이스의 대부분은 마스터-슬레이브라고 하는 기능을 갖추고 있음
- 이러한 구성에서는 단일 노드가 마스터로 지정되어 읽기 및 쓰기 작업을 수행 할 수 있고
- 나머지 노드는 슬레이브 역할을 하며 읽기 작업만 수행할 수 있음
- 마스터-슬레이브 단점
- 지연은 특히 분산됨 팀의 주요 문제가 될 수 있음
- 응용 프로그램을 확장해야 할 경우 비용이 크게 상승 할 수 있음
- 가용성마저 저하 될 수 있음
- 마스터 노드에 장애가 발생하면 관리자가 새 마스터를 지정할 때까지 데이터베이스 작업이 중지 될 수 있음
Masterless
- 마스터리스 아키텍처로 구축 된 Apache Cassandra는 위와 같은 단점이 없음
- 데이터 복제를 담당하는 단일 노드가 없고 모든 노드가 동일함
- 링 또는 데이터베이스 클러스터에 참여하는 모든 노드에 자동으로 데이터 분재를 제공
- 데이터는 모든 노드에서 투명하게 분할되므로 개발자나 관리자가 클러스터 전체에 데이터를 배포하기 위해 프로그래밍 하지 않아도 됨
- 대신 모든 노드가 읽기 및 쓰기 작업을 수행
- 성능이 향상되고 데이터베이스에 복원력이 추가 됨
확장성
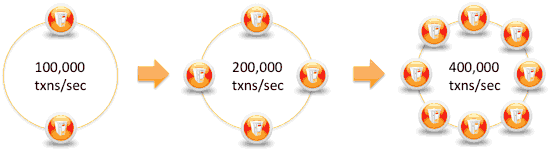
기존 환경에서 응용 프로그램의 확장은 대개 시간이 많이 걸리고 비용이 많이 드는 프로세스이며 일반적으로 확장을 통해 수행됩니다. 반면 Cassandra를 사용하면 클러스터에 노드를 추가하기 만하면 용량을 선형으로 늘릴 수 있습니다. 예를 들어, 2 개의 노드가 초당 100,000 개의 트랜잭션을 처리 할 수있는 경우 8 개의 노드가 초당 400,000 개의 트랜잭션을 처리 할 수 있습니다.
고 가용성 및 내 결함성
모든 Cassandra 노드는 읽기 및 쓰기 작업을 수행 할 수 있으므로 데이터가 빠르게 복제 하이브리드 클라우드 환경 및 지역, 노드에 장애가 발생하면 사용자는 가장 가까운 정상 노드로 자동 라우팅됩니다. 심지어 장애가 발생하더라도 응용 프로그램이 설계된대로 작동하기 때문에 노드가 오프라인 상태가 된 것을 알지 못합니다.
결과적으로 응용 프로그램을 항상 사용할 수 있으며 데이터에 항상 액세스 할 수 있으며 손실되지 않는다. 또한 Cassandra는 수동 수리없이 문제가 발생한 직후 문제를 실제로 해결할 수있는 기본 제공 수리 서비스를 제공합니다. 노드가 고장 나더라도 생산성을 높이지 않아도 됩니다.
고성능
함께 찍은 카산드라의 마스터리스 아키텍처 기본적으로 분산 된 데이터 복제는 트랜잭션에 포함 된 데이터의 양에 관계없이 대규모로 고성능을 제공합니다. 직원은 위치에 상관없이 생산성을 유지할 수있을뿐만 아니라, 직원 수와 동시에 사용하는 사람들도 앱과 상호 작용하는 긍정적인 경험을 누릴 수 있습니다.
단점
- Join이나 Transaction을 지원하지 않음
- Index 등의 검색을 위한 기능도 매우 단출
- RDBMS와 같은 Paging을 구현하는 것이 힘들고 Keyspace나 Table 등을 과도하게 생성할 경우 Memory Overflow가 발생할 수 있음
Apache Cassandra vs 기존 관계형 데이터베이스
| 관계형 데이터베이스 | 카산드라 |
|---|---|
| 적당한 수신 데이터 속도 처리 | 높은 수신 데이터 속도 처리 |
| 복잡하고 중첩 된 거래 지원 | 간단한 거래 지원 |
| 장애 조치를 통한 단일 장애 지점 | 단일 실패 지점이 없고 지속적인 가동 시간 |
| 중간 규모의 데이터 볼륨 지원 | 매우 높은 데이터 볼륨 지원 |
| 중앙 집중식 배포 | 분산 배치 |
| 주로 한 위치에 기록 된 데이터 | 여러 위치에서 작성된 데이터 |
| 읽기 확장 성 지원 (일관성 희생) | 읽기 및 쓰기 확장 성 지원 |
| 수직 확장 방식으로 배포 | 수평 확장 방식으로 배포 |
데이터 모델
내부 데이터 구조
카산드라 데이터 모델은 스키마 선택적 열 지향 데이터 모델입니다.
즉, 관계형 데이터베이스와 달리 각 행에 동일한 열 집합이 없어도되므로 응용 프로그램에 필요한 모든 열을 미리 모델링할 필요가 없습니다.
카산드라 데이터 모델은 키 스페이스(데이터베이스와 유사), 열 패밀리(관계형 모델의 테이블과 유사), 키와 열로 구성됩니다.
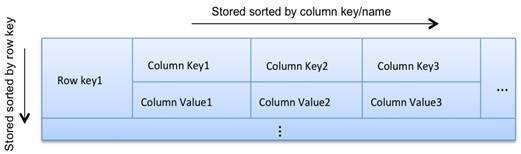
각 열 계열에 대해 관계형 테이블을 생각하지 마세요. 대신 중첩 된 맵 데이터 구조를 생각하세요. 중첩 정렬 맵은 관계형 테이블보다 더 정확하며 카산드라 데이터 모델에 대한 올바른 결정을 내리는데 도움이 됩니다.
Map<RowKey, SortedMap<ColumnKey, ColumnValue>>맵은 효율적인 키 조회를 제공하고 정렬 된 특성은 효율적인 스캔을 제공합니다. 카산드라에서는 행 키와 열 키를 사용하여 효율적인 조회 및 범위 검색을 수행 할 수 있습니다. 열 키의 수는 제한이 없습니다. 즉, 넓은 행을 가질 수 있습니다. 키 자체는 키 이름의 일부로 값을 보유 할 수 있습니다. 즉, 값이없는 열을 가질 수 있습니다.
CQL
카산드라는 SQL과 유사한 CQL (Cassandra Query Language)를 사용합니다. SQL과 마찬가지로 명령문은 데이터를 변경하거나, 데이터를 검색하거나, 데이터를 저장하거나, 데이터가 저장되는 방식을 변경합니다.
SELECT * FROM MyTable;
UPDATE MyTable
SET SomeColumn = 'Some Value'
WHERE columnName = 'Something Else';CQL을 사용하여 작성된 키 공간, 열 및 테이블 이름은 큰 따옴표로 묶지 않으면 대소문자를 구분하지 않습니다. 대문자를 사용하여 이러한 객체의 이름을 입력하면 카산드라는 이름을 소문자로 저장합니다. 큰 따옴표를 사용하여 케이스를 강제 실행할 수 있습니다.
CREATE TABLE test (
Foo int PRIMARY KEY,
"Bar" int
);마무리
오늘은 카산드라가 무엇인지 간략히 알아봤습니다.
다음에는 카산드라 인덱스와 데이터 복제, 동시성 등에 대해 알아보겠습니다.
참고
- 하이브리드 클라우드란 둘 이상의 퍼블릭 클라우드와 프라이빗 클라우드를 환경이 조합된 것↩